Эволюция языковых моделей: от чат-ботов до ИИ будущего
В свете бурного развития нейросетей, важно указать, что статья написана в начале 2025 года, и буквально через год ситуация может быть совершенно иной (как было год назад, скажем). Следите за новостями;), но не упускайте историю.

Языковые модели — это один из самых динамичных и впечатляющих разделов искусственного интеллекта. Они эволюционировали от примитивных программ, способных давать односложные ответы, до сложных систем, таких как GPT-4, которые могут поддерживать разговор, писать эссе, создавать код и даже имитировать человеческое мышление. Давайте проследим этот путь, чтобы понять, как технологии шаг за шагом приближались к современным достижениям.
Первые шаги: Простые чат-боты (1960–1990-е годы)
Одним из первых примеров языковой модели был чат-бот ELIZA, созданный Джозефом Вейценбаумом в Массачусетском технологическом институте в 1966 году. Этот бот мог имитировать разговор с психотерапевтом, задавая вопросы типа "Как вы себя чувствуете?" или перефразируя фразы пользователя. Хотя ELIZA не обладала реальным пониманием текста, она показала, что компьютеры могут взаимодействовать с людьми на уровне языка.
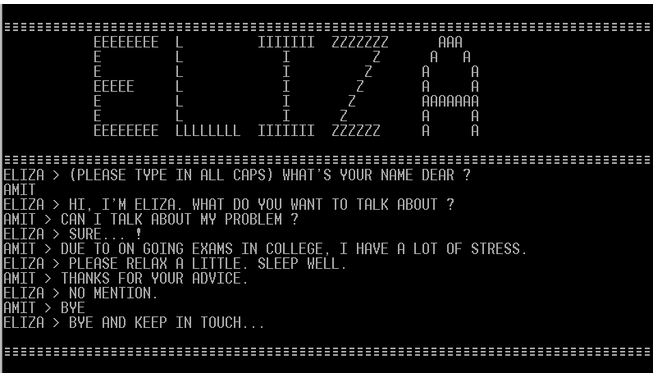 ELIZA ведет беседу
ELIZA ведет беседу
ELIZA работала на основе правил: она искала ключевые слова в предложениях и отвечала заранее запрограммированными шаблонами. Это была революция своего времени, но модель не могла адаптироваться или учиться, а длительный разговор приводил к столкновению с ее ограниченными возможностями.
На протяжении 80-х годов были созданы различные версии чат-ботов. Следующим по известности был Parry, созданный в 1972 году Кеннетом Колби, профессором психиатрии Стэнфордского университета. Остались записи "разговоров" между собой этих двух моделей, более того Пэрри прошел тест Тьюринга с результатом 52%.
Развитие правил и статистики (1990–2000-е годы)
В 1990-х годах появились более сложные системы, использующие статистические методы для анализа текста. Например, программы начали использовать частотность слов и их сочетаний для предсказания следующего слова в предложении.
Пример такой модели — ALICE (Artificial Linguistic Internet Computer Entity) (разработана в 1995), которая использовала AIML (Artificial Intelligence Markup Language - язык разметки искусственного интеллекта) для описания правил взаимодействия с пользователем. ALICE могла поддерживать разговор на некоторое количество тем, но её возможности всё ещё были ограничены жёсткими правилами. Другие программисты могли использовать ALICE для создания собственных чат-ботов, что быстро развивало эту технологию.
Эра машинного обучения (2010-е годы)
С развитием машинного обучения и доступности больших данных началась новая эпоха. Языковые модели стали использовать нейронные сети, которые могли обучаться на огромных массивах текста.
Ключевые примеры:
- Word2Vec (2013): Представлял слова в виде многомерных векторов, сохраняя их семантические связи.
- Seq2Seq (2014): Архитектура Sequence-to-Sequence позволила создавать модели, которые переводили текст с одного языка на другой.
Внедрение искусственного интеллекта и разработка чат-ботов с открытым исходным кодом привели к быстрым улучшениям. Siri от Apple, Google Assistant от Google и Алиса от Яндекс — всё это примеры чат-ботов, которые действуют как личные помощники в ваших компьютерах, телефонах или других устройствах.
Трансформеры и революция в NLP (2017–2020 годы)
В 2017 году исследователи из Google представили архитектуру Transformer, которая изменила подход к обработке естественного языка. Трансформеры использовали механизм внимания, позволяющий модели сосредотачиваться на важных частях текста и лучше понимать контекст.
Примеры моделей:
- BERT (2018): Анализирует текст в обоих направлениях (слева направо и справа налево).
- GPT-1 (2018): Первая версия Generative Pre-trained Transformer, которая могла генерировать связный текст.
GPT и масштабирование (2018–2025 годы)
Каждая новая версия GPT становилась мощнее:
- GPT-2 (2019): Содержала 1,5 миллиарда параметров и могла генерировать связные тексты.
- GPT-3 (2020): Содержала 175 миллиардов параметров и стала одной из самых мощных языковых моделей на тот момент
- ChatGPT (2022): на базе GPT-3.5. Эта версия быстро стала популярной, набрав более 1 миллиона пользователей за пять дней и достигнув 100 миллионов к январю 2023 года, став самым быстрорастущим приложением в истории
- ChatGPT-4 (03.2023): многомодальная модель, обрабатывающая текст и изображения, с улучшенными способностями в программировании, рассуждениях и творчестве. Эта модель укрепила позиции ChatGPT как лидера в области чат-ботов ИИ
- ChatGPT-4.1 (04.2025): (кодовое название Quasar Alpha), которая предлагает существенные улучшения по всем направлениям от кодинга до мультимодальности
Как ChatGPT может помочь в изучении математики?
Что дальше? (2025 год)
В 2025 году ожидается значительный скачок в развитии языковых моделей. Одним из ключевых трендов станет дальнейшее масштабирование: количество параметров в новых моделях может достигать 1 триллиона (в сравнении с 175 миллиардами у GPT-3). Это позволит моделям работать с более сложными задачами, такими как многопоточное программирование, генерация мультимодальных данных (текст + видео) и решение научных проблем.
Другие модели ИИ
- Llama 3 (Meta): серия больших языковых моделей (LLM) от Meta AI, выпущенных в апреле 2024 года для исследований и коммерческого использования под открытой лицензией. Модели предназначены для обработки текста, генерации ответов и выполнения задач, таких как перевод, программирование и анализ данных.
- Gemini (Google): Модель от Google, которая объединяет текстовые и мультимодальные возможности, с количеством параметров, превышающим 300 миллиардов. Она уже демонстрирует высокую производительность в задачах анализа видео и аудио.
- Claude (Anthropic): Эта модель фокусируется на этичности и безопасности. Три основные модели: Haiku (компактная), Sonnet (сбалансированная), Opus (мощная, ~500B параметров, сравнима с GPT-4). Есть мультимодальность (текст и изображения), особенно хороша в работе с текстами (естественный язык и контекстное понимание).
Больше данных и параметров
Масштабирование остаётся ключевым фактором прогресса. Например:
- Новые модели будут обучаться на корпусах данных размером более 100 триллионов токенов (для сравнения, GPT-3 обучался на ~45 тератокенах).
- Количество шагов обработки (layers) в нейронных сетях увеличится до 100–150 слоёв, что позволит моделям лучше понимать контекст и долгосрочные зависимости.
Однако рост числа параметров создаёт проблемы с вычислительными ресурсами. Для обучения модели с триллионом параметров требуется около 100 000 GPU, что делает такие проекты доступными только крупным компаниям.
Персонализация
Будущие модели будут адаптироваться под конкретных пользователей. Например:
- Функция памяти: Модели смогут запоминать предпочтения пользователя и адаптировать свои ответы. Например, если вы часто спрашиваете о рецептах, модель начнёт предлагать блюда, основываясь на ваших предпочтениях.
- Гибридные системы: Комбинация локальных (на устройстве) и облачных моделей позволит обеспечить персонализацию без ущерба для конфиденциальности.
Объяснение решений
Одна из ключевых задач — сделать модели более прозрачными. В 2025 году ожидаются значительные улучшения в этой области:
- Explainable AI (XAI): Новые методы позволят моделям объяснять свои решения на уровне "человеческого" понимания. Например, если модель рекомендует определённую стратегию лечения, она сможет показать, какие данные и исследования легли в основу решения.
- Анализ цепочек рассуждений: Модели будут предоставлять пошаговое объяснение процесса принятия решений, что особенно важно в медицине, юриспруденции и финансах.
Интеграция с другими технологиями
Языковые модели будут всё больше взаимодействовать с роботами, автономными системами и другими ИИ. Конкретные примеры:
- Автономные автомобили: Языковые модели помогут интерпретировать команды водителя и реагировать на изменения окружающей среды.
- Роботы-ассистенты: Комбинация языковых моделей и компьютерного зрения позволит роботам выполнять сложные задачи, например, готовить еду или убирать дом.
- Мультимодальные системы: Модели смогут обрабатывать не только текст, но и видео, аудио и 3D-данные. Например, Gemini уже демонстрирует возможность создания коротких фильмов на основе текстового описания.
Этика и безопасность
В 2025 году ожидается усиление внимания к этике использования ИИ:
- Защита данных: Новые модели будут использовать дифференциальную приватность, чтобы защитить личную информацию пользователей.
- Контроль над генерацией: Разработчики внедрят механизмы, предотвращающие создание вредоносного контента (например, дезинформации или фейковых новостей).
- Открытость: Больше компаний будут публиковать свои модели в открытый доступ, чтобы стимулировать исследования и развитие сообщества.
Новые задачи и применения
- Научные исследования: Модели будут помогать учёным анализировать большие объёмы данных, формулировать гипотезы и даже предлагать эксперименты.
- Образование: Персонализированные системы обучения смогут адаптироваться под уровень знаний ученика и предлагать индивидуальные программы.
- Творчество: Генерация музыки, фильмов, игр и произведений искусства станет ещё более доступной и качественной.
Эволюция языковых моделей — это история постоянного прогресса. От простых чат-ботов до GPT-4.1 и далее, каждая новая модель открывает новые горизонты. Сегодня мы стоим на пороге эры, где искусственный интеллект становится не просто помощником, а полноценным партнёром в решении сложных задач.